 LiU Homepage
LiU Homepage
Cognitive Vision Research
It has for a long time been believed in vision research that a system should have a structure like in the figure below.
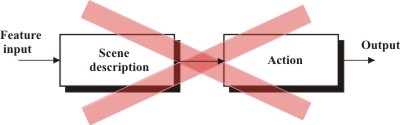
The first part should use the incoming image information to produce a description of the image, where different objects are recognized and assigned to the proper categories, together with information about position and other relevant parameters. A second unit would now use this information to produce actions into the physical world, e.g. to implement a robot.
This structure has not worked out very well for reasons which will become apparent. It turns out that in fact the order between the parts shall be the opposite. See figure below.

The first part of the system is a reactive percept-to-action mapper. After this follows, if necessary for the application, a part which performs a symbolic processing for categorization and reasoning, in brief what we refer to as AI, and communication. For completeness, we will give a slightly more detailed structure diagram, around which the further discussion will center.
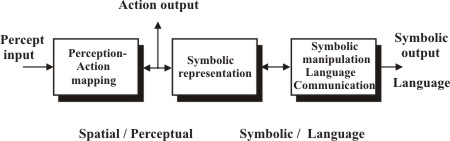
The distinctive characteristic of this structure is that percepts are mapped directly onto actions, rather than descriptions, as it was in the first figure. The reason is that this strategy allows the system to learn objects and other aspects of the environment by itself. Descriptions, of which assignment to category is one example, are generated in the symbolic part of the structure, for communication to other systems or for use in symbolic reasoning.
For a detailed discussion of these issues, reference is made to ECVision Research Background Document, and articles [Granlund99a] and [Granlund99b], but a few major points will be listed here:
- Learning of an object is not just to identify its category, but to identify its position, pose, orientation, and to learn what action complexes it can be linked to for handling. This is what understanding of an object implies. This is also what is activated as we see e.g. a chair. Not the geometric properties of it.
- Learning implies the association between the system?s own state including its action state and the perceptual state. This is driven from the action side rather than from the percept side. The reason is that the action space or the system state space is immensely less complex than the percept space.
- The symbolic representation shall emerge from the action representation, rather than from any descriptive, geometric representation. There are strong indications that this is the way it is done in the human brain --- we perceive consciously the external world in terms of the actions we can perform with respect to it.
- The symbolic representation implies a stripping off of spatial context to produce sufficiently invariant packets of information to be handled symbolically or to be communicated. This may also require the introduction of symbolic contextual entities.
- Conversely, symbolic information can be made to control the perception-action structure by conversion of the symbol structure to spatial and other detailed context parameters for the perception-action structure
The preceding is exactly the strategy which has very successfully been employed by biological systems.
The workings of the symbolic structure and its different
implementations, such as for planning, language, communication, etc.,
is well documented in literature and will be omitted in this
exposition. What is important to observe is that the spatial/cognitive
domain and the symbolic/language domain are two different worlds,
where different rules and methods apply.
Informationsansvarig: Gösta H. Granlund
Senast uppdaterad: 2012-06-16
